When I try to open my php file located in my PC (e.g., localhost/kaz/indexpage.php, I get the following warning message. The message says that my connection "is not private."

Statsitics, Research Methods, SAS, R, HLM, Rasch model
When I try to open my php file located in my PC (e.g., localhost/kaz/indexpage.php, I get the following warning message. The message says that my connection "is not private."
The default character set is latin1_swedish_ci . I will use utf8_general_ci instead since it seems to be the most up-to-date character set and the article I found (see reference) suggests we do. However, I have never encountered an issue just using latin1_swedish_ci for Japanese materials. My questions are:
Reference:
https://mediatemple.net/community/products/dv/204403914/default-mysql-character-set-and-collation
I need quotes when specifying a date value.
SELECT *
FROM purchases
WHERE purchased_at <= "2018-11-01";
Pick up rows whose values contain "pudding":
SELECT *
FROM purchases
WHERE name like "%pudding%";
You can use NOT:
SELECT *
FROM purchases
WHERE NOT character_name="Ken";
Another example of NOT:
SELECT *
FROM purchases
WHERE NOT name like "%pudding%";
SELECT *
FROM purchases
WHERE price IS NOT NULL;
Ordering observations
SELECT *
FROM purchases
WHERE character_name = "Ken"
ORDER BY price DESC;
NOT
SELECT *
FROM purchases
WHERE NOT character_name = "Ken";
SELECT *
FROM purchases
WHERE price IS NULL;
SELECT *
FROM purchases
ORDER BY price DESC
LIMIT 5;
Counting the row of observations
This counts non-missing values.
SELECT COUNT(name)
FROM purchases;
This counts the number of rows.
SELECT COUNT(*)
FROM purchases;
Using the where statement:
SELECT COUNT(*)
FROM purchases
WHERE character_name="Ken"
;
Picking up the observation whose value is a maximum value
SELECT name, max(price)
FROM purchases
WHERE character_name="Ken"
;
GET THE SUM PER GROUP
SELECT SUM(price), purchased_at
FROM purchases
GROUP BY purchased_at
;
SELECT COUNT(*), purchased_at
FROM purchases
GROUP BY purchased_at;
SELECT SUM(price), purchased_at
FROM purchases
WHERE character_name="Ken"
GROUP BY purchased_at
;
SELECT SUM(price), purchased_at
FROM purchases
GROUP BY purchased_at
HAVING sum(price) > 20;
This picks up cases with a condition (in this case, whoever had a higher score than the guy Will).
SELECT name
FROM players
WHERE goals > (
-- Write an SQL statement below to get Will's score
SELECT goals
FROM players
WHERE name = "Will"
)
;
SELECT name,goals
FROM players
WHERE goals > (
SELECT AVG(goals)
FROM players
)
;
Using AS:
SELECT name AS "180 cm or taller"
FROM players
WHERE height >= 180
;
SELECT SUM(goals) AS "total team score"
FROM players
;
SELECT *
FROM countries
WHERE rank < (
SELECT rank
FROM countries
WHERE name="Japan"
)
;
Merging two tables:
SELECT *
FROM players
-- Add a name to the combined table
JOIN countries
-- Add a join condition
ON players.country_id = countries.id
;
SELECT players.name, countries.name
FROM players
JOIN countries
ON players.country_id = countries.id
;
SELECT countries.name, SUM(goals)
FROM players
JOIN countries
ON players.country_id = countries.id
GROUP BY countries.name
;
SELECT *
FROM players
JOIN teams
ON players.previous_team_id = teams.id
;
SELECT players.name AS "player name", teams.name AS "team (last year)"
FROM players
JOIN teams
ON players.previous_team_id = teams.id
;
SELECT *
FROM players
LEFT JOIN teams
ON players.previous_team_id =teams.id
;
SELECT players.name AS "player name", teams.name AS "team (last year)"
FROM players
LEFT JOIN teams
ON players.previous_team_id = teams.id
;
SELECT *
FROM players
JOIN countries
ON players.country_id = countries.id
LEFT JOIN teams
ON players.previous_team_id = teams.id
;
SELECT players.name AS "Player name", players.height AS "height"
FROM players
WHERE height > (
SELECT AVG(height)
FROM players
)
select name, price
from items
order by price desc
;
-- get all rows that contain the string "shirt"
SELECT *
FROM items
WHERE name like "%shirt%"
;
SELECT name, price, MAX(price - cost)
FROM items;
SELECT name, price
FROM items
WHERE price > (
SELECT price
FROM items
WHERE name = "grey hoodie"
);
In programming, sorting can occur in ascending way or ascending way. I often get confused by this distinction when I use SAS PROC SORT. To summarize:
Sorting by ascending order means:
1
2
3
4
5
Sorting by descending order means:
5
4
3
2
1
PROC SORT:
The following is an example of how descending can be specified. The first SORT procedure sorts the data by first DateModified by natural sequence and TimeModified by the descending order. This means that older data (defined by TimeModified) in the presence of duplicate rows (the same date) will appear first. The second SORT procedure has the nodupkey option, which means that only the first and thus oldest data will be kept and the rest are deleted if the data came from the same date.
proc sort;by Table1_ID child_number DateModified descending TimeModified;
run;
proc sort nodupkey;by Table1_ID child_number;
run;
PROC LOGISTIC
It is common to code the binary outcome as 0 (failure) and 1 (success); however, PROC LOGISTIC models the occurrence of 1 not 0.
<continued>
The following did not work well. When I find a solution, I will update this post.
***
When I removed a column from a table, ACCESS gave me a message saying I first needed to remove the link(s) from the relationship window.
This means that a column I wanted to delete had an existing relationship (or relationshipS) with another table(s). The following is the summary of what I did.
I have to break these link(s) first. The problem is when there are a lot of tables in the relationship window, relevant tables and links between them are hard to locate.
I suspect in some cases some tables are hidden for an unknown reason.
Pull the table away from other tables, so you can clearly see the links themselves. Click each one of them to see with which table the table is linked. You will eventually find the table you are looking for. Remove the links to break the relationships. Then you can delete the columns you want to delete.
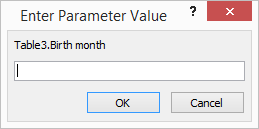
Up to this point, I thought the problem was solved, but I keep getting the message, "Enter Parameter Value." "Birth month" as it appears in the message graphic is one of the two variables/columns I deleted. I got stuck.
I found this video, which may or may not be relevant to solve my problem.
Acknowledgement: Thanks KM for supplying this answer.
Question:
I am comparing a date variable and date and time variable and I am not getting the right answer.
Below, I am creating a variable CUT_DATE. I compare it against DateModified, which includes year, month, date, and time. I am not getting the right answer. Please see the table after the syntax. I should get “0” in USE_THIS (the highlighted row). I think one solution may be to create CUT_DATE based on year, month, date, AND TIME. What function do I use for this instead of MDY?
/*REMOVE ALL DATA ENTERED BEFORE A FIXED DATE*/
%let _year=2018;
%let _month=10;
%let _date=01;
/*table 1*//*table 1*//*table 1*//*table 1*/
/*table 1*//*table 1*//*table 1*//*table 1*/
data table1b;set access1.table1;
cut_date=mdy(&_month,&_date,&_year);
FORMAT cut_date date9. ;
USE_THIS=0;
if DateModified > cut_date then USE_THIS=1;
run;
DateModified cut_date USE_THIS
31OCT2018:00:00:00 1-Oct-18 1
31OCT2018:00:00:00 1-Oct-18 1
05MAR2018:00:00:00 1-Oct-18 1
31OCT2018:00:00:00 1-Oct-18 1
31OCT2018:00:00:00 1-Oct-18 1
ANSWER from SAS:
You can use the DHMS function to create a datetime value. Another alternative would be to use the DATEPART function on the DateModified variable.
Example:
data table1b;
set table1;
cut_date=mdy(&_month,&_date,&_year);
cut_date1=dhms(mdy(&_month,&_date,&_year),0,0,0);
FORMAT cut_date date9. cut_date1 datetime18. ;
USE_THIS=0;
use_this1=0;
if DateModified > cut_date1 then USE_THIS=1;
if datepart(datemodified) > cut_date then use_this1=1;
run;
I got this advice from someone when I needed to know how to apply a procedure on a subgroup of subjects within the analysis dataset. Thanks.
library(dplyr) library(magrittr)
ols_result <- data %>% dplyr::filter(year=1) %>% lm(y~x,.) summary(ols_result)
dplyr::filter(year==1)